
WOUTER VAN ROSSEM

Research
- Research questions and conceptual framework
My work for the Processing Citizenship project is connected to WP2 (“To analyse and compare information systems used to register migrants across diverse Hotspots”). The method and software tool developed for this was used to conduct a script analysis for WP3 comparing “intended migrants” identities “inscribed” in information systems with actual migrants practices of resistance to being registered. Furthermore, my research contributes to answer WP4,RQ7A (How are relationships between EU and MS enacted through efforts to achieve interoperability?) by investigating the interoperability of identity data between EU and MS systems.
More generally, my research focuses on the complex phenomenon of matching identity data. For instance, are you aware that from booking to boarding a flight, your personal data is being matched against various police watchlists to identify potentially risky travellers? To make this matching possible, sophisticated algorithms are used to deal with uncertainties in their data—think: typing errors, transcription variations of names, etc.
I am particularly interested in how transnational security infrastructures shape and are shaped by these technological advancements. My main research question therefore asks:
“How are practices and technologies for matching identity data in population management shaping and shaped by transnational security infrastructures?”
In my dissertation introduce a conceptual framework that aims to analyse data matching from four different perspectives:
- how types of data collected about people can be compared and what this tells us about how organisations can search, match, and use this data,
- how within organisations search and match for data about people,
- how such identity data is matched between organisations,
- how, at the same time with matching identity data, data matching technologies and practises evolve.
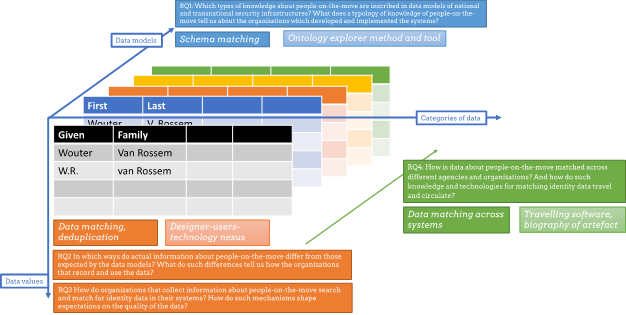
Figure X visualizes this conceptual framework together with the sub-questions of my main research question. The three axes capture different dimensions of data: data models (z), categories of data (x), and data values (y). These three axes can be paired as follows:
- (data models z, categories of data x): represents the identification of semantic similarities and differences between different data models and their categories of data. (1)
- (categories of data x, data values y): relates to the categories of data and their actual values in databases, which may not always correspond to the expectations of the data models and impact the matching of identity data. (2)
- (data models z, data values y): addresses matching of identity data across organizations and agencies’ systems and databases. Furthermore, it relates to how not only identity data are matched across systems, but also how technologies and practices for data matching travel across organizations. ( 3 & 4)
- Methods
To trace the matching of identity data in security infrastructures, I took advantage of well-established methods from the areas sociotechnical research to investigate the relations between the technologies, users, and organizations. Hence, I draw on data gathered through fieldwork — interviews, documents, field notes — at a supplier of a data matching software that is used by EU and Member State authorities.
- Outputs
The Ontology explorer
One of the main outcomes of my research has been development of the Ontology Explorer together with Prof. Annalisa Pelizza. The Ontology Explorer was devised to understand how people are “inscribed” in information systems: which assumptions are made about them, and which possibilities are excluded by design. The outputs and results of this work is split up in a few outputs.
First, the following article introduces the methodology of the “Ontology Explorer” to analyse data models underpinning information systems.
Van Rossem, Wouter, and Annalisa Pelizza. 2022. ‘The Ontology Explorer: A Method to Make Visible Data Infrastructures for Population Management’. Big Data & Society 9 (1): 1–18. https://doi.org/10.1177/20539517221104087.
Second, the following repository contains the source code for the JavaScript-based open-source tool of the Ontology Explorer methodology. A version is hosted on the Processing Citizenship website at https://processingcitizenship.eu/ontology-explorer/.
Van Rossem, Wouter. 2021. ‘Ontology-Explorer’. Zenodo. https://doi.org/10.5281/zenodo.4899316.
Expertise
My original academic background comes from a Msc in Applied Computer Science at the Vrije Universiteit Brussel (Belgium). Previous to this PhD I also worked as a software engineer in several companies in banking, utilities, and streaming television. This varied background of both theoretical and hands-on knowledge allowed me to develop the interdisciplinary method of the “Ontology explorer” for analysing and comparing data models underpinning information systems.
Furthermore, how knowledge, rules, and processes are embedded in information systems and the implications this has on governance of IT systems, has interested me since my master dissertation for an additional Msc in Management. In this context I conducted research on the way rules defined by business processes are deeply embedded in IT systems, and the challenges this causes.
During my PhD I took part in the brilliant Dutch Graduate School Science, Technology and Modern Culture (WTMC) which has served as my main introduction into the field of STS. Since then, my main interests has been in the fields of classification and (critical) data studies (e.g., the work of Susan Leigh Star, Geoffrey C. Bowker, Evelyn Ruppert, Yanni Alexander Loukissas), infrastructure studies (e.g., Paul Edwards, David Ribes), global software development (e.g., Robin Williams, Neill Pollick), and the interlinkages of these fields with security, migration, and border control (e.g., Huub Dijstelbloem, Irma van der Ploeg).
Inspirations
Even though I was not aware at the time, my experience as a trainee in the text and data mining unit at the Joint Research Centre of the European Commission in Italy (2017–2018) provided my first practical introduction into the difficulties of matching data. During this traineeship I was fortunate to work with, among other, Dr. Guillaume Jacquet and Dr. Ralf Steinberger, both experts on text analysis and (named) entity recognition, in the context of multilingual news analysis of online news sources for the Europe Media Monitor (EMM) tool.
This formative experience was crucial to understand the links between the focus on improving data quality in the information systems of security, migration and border control, and the social, technical, institutional complexities of matching identity data. More research on these often unknown and invisible technologies is furthermore warranted as they are deployed in systems all over the world.
- Research questions and conceptual framework
My work for the Processing Citizenship project is connected to WP2 (“To analyse and compare information systems used to register migrants across diverse Hotspots”). The method and software tool developed for this was used to conduct a script analysis for WP3 comparing “intended migrants” identities “inscribed” in information systems with actual migrants practices of resistance to being registered. Furthermore, my research contributes to answer WP4,RQ7A (How are relationships between EU and MS enacted through efforts to achieve interoperability?) by investigating the interoperability of identity data between EU and MS systems.
More generally, my research focuses on the complex phenomenon of matching identity data. For instance, are you aware that from booking to boarding a flight, your personal data is being matched against various police watchlists to identify potentially risky travellers? To make this matching possible, sophisticated algorithms are used to deal with uncertainties in their data—think: typing errors, transcription variations of names, etc.
I am particularly interested in how transnational security infrastructures shape and are shaped by these technological advancements. My main research question therefore asks:
“How are practices and technologies for matching identity data in population management shaping and shaped by transnational security infrastructures?”
In my dissertation introduce a conceptual framework that aims to analyse data matching from four different perspectives:
- how types of data collected about people can be compared and what this tells us about how organisations can search, match, and use this data,
- how within organisations search and match for data about people,
- how such identity data is matched between organisations,
- how, at the same time with matching identity data, data matching technologies and practises evolve.
Figure X visualizes this conceptual framework together with the sub-questions of my main research question. The three axes capture different dimensions of data: data models (z), categories of data (x), and data values (y). These three axes can be paired as follows:
- (data models z, categories of data x): represents the identification of semantic similarities and differences between different data models and their categories of data. (1)
- (categories of data x, data values y): relates to the categories of data and their actual values in databases, which may not always correspond to the expectations of the data models and impact the matching of identity data. (2)
- (data models z, data values y): addresses matching of identity data across organizations and agencies’ systems and databases. Furthermore, it relates to how not only identity data are matched across systems, but also how technologies and practices for data matching travel across organizations. ( 3 & 4)
- Methods
To trace the matching of identity data in security infrastructures, I took advantage of well-established methods from the areas sociotechnical research to investigate the relations between the technologies, users, and organizations. Hence, I draw on data gathered through fieldwork — interviews, documents, field notes — at a supplier of a data matching software that is used by EU and Member State authorities.
- Outputs
The Ontology explorer
One of the main outcomes of my research has been development of the Ontology Explorer together with Prof. Annalisa Pelizza. The Ontology Explorer was devised to understand how people are “inscribed” in information systems: which assumptions are made about them, and which possibilities are excluded by design. The outputs and results of this work is split up in a few outputs.
First, the following article introduces the methodology of the “Ontology Explorer” to analyse data models underpinning information systems.
Van Rossem, Wouter, and Annalisa Pelizza. 2022. ‘The Ontology Explorer: A Method to Make Visible Data Infrastructures for Population Management’. Big Data & Society 9 (1): 1–18. https://doi.org/10.1177/20539517221104087.
Second, the following repository contains the source code for the JavaScript-based open-source tool of the Ontology Explorer methodology. A version is hosted on the Processing Citizenship website at https://processingcitizenship.eu/ontology-explorer/.
Van Rossem, Wouter. 2021. ‘Ontology-Explorer’. Zenodo. https://doi.org/10.5281/zenodo.4899316.
Expertise
My original academic background comes from a Msc in Applied Computer Science at the Vrije Universiteit Brussel (Belgium). Previous to this PhD I also worked as a software engineer in several companies in banking, utilities, and streaming television. This varied background of both theoretical and hands-on knowledge allowed me to develop the interdisciplinary method of the “Ontology explorer” for analysing and comparing data models underpinning information systems.
Furthermore, how knowledge, rules, and processes are embedded in information systems and the implications this has on governance of IT systems, has interested me since my master dissertation for an additional Msc in Management. In this context I conducted research on the way rules defined by business processes are deeply embedded in IT systems, and the challenges this causes.
During my PhD I took part in the brilliant Dutch Graduate School Science, Technology and Modern Culture (WTMC) which has served as my main introduction into the field of STS. Since then, my main interests has been in the fields of classification and (critical) data studies (e.g., the work of Susan Leigh Star, Geoffrey C. Bowker, Evelyn Ruppert, Yanni Alexander Loukissas), infrastructure studies (e.g., Paul Edwards, David Ribes), global software development (e.g., Robin Williams, Neill Pollick), and the interlinkages of these fields with security, migration, and border control (e.g., Huub Dijstelbloem, Irma van der Ploeg).
Inspirations
Even though I was not aware at the time, my experience as a trainee in the text and data mining unit at the Joint Research Centre of the European Commission in Italy (2017–2018) provided my first practical introduction into the difficulties of matching data. During this traineeship I was fortunate to work with, among other, Dr. Guillaume Jacquet and Dr. Ralf Steinberger, both experts on text analysis and (named) entity recognition, in the context of multilingual news analysis of online news sources for the Europe Media Monitor (EMM) tool.
This formative experience was crucial to understand the links between the focus on improving data quality in the information systems of security, migration and border control, and the social, technical, institutional complexities of matching identity data. More research on these often unknown and invisible technologies is furthermore warranted as they are deployed in systems all over the world.
Even though I was not aware at the time, my experience as a trainee in the text and data mining unit at the Joint Research Centre of the European Commission in Italy (2017–2018) provided my first practical introduction into the difficulties of matching data. During this traineeship I was fortunate to work with, among other, Dr. Guillaume Jacquet and Dr. Ralf Steinberger, both experts on text analysis and (named) entity recognition, in the context of multilingual news analysis of online news sources for the Europe Media Monitor (EMM) tool.
This formative experience was crucial to understand the links between the focus on improving data quality in the information systems of security, migration and border control, and the social, technical, institutional complexities of matching identity data. More research on these often unknown and invisible technologies is furthermore warranted as they are deployed in systems all over the world.